
KI-Agenten, Reinforcement Learning und Heuristiken in der Bestandsoptimierung
In der heutigen volatilen Marktlandschaft ist eine präzise Bestandsführung über mehrstufige Lieferketten hinweg kein operativer Vorteil mehr, sondern eine strategische Überlebensnotwendigkeit.
Von KICompass
1. Einleitung und Problemstellung im Multi-Echelon SCM
In der heutigen volatilen Marktlandschaft ist eine präzise Bestandsführung über mehrstufige Lieferketten hinweg kein operativer Vorteil mehr, sondern eine strategische Überlebensnotwendigkeit. Die herkömmliche Steuerung durch starre Heuristiken versagt zunehmend vor der Komplexität moderner Netzwerke, in denen Peitscheneffekte (Bullwhip-Effekte) und unvorhersehbare Nachfrageschwankungen massives Kapital binden oder durch Backlogs die Kundenzufriedenheit erodieren. Unsere Benchmark-Analyse belegt zweifelsfrei, dass die Transformation hin zu autonomen KI-Systemen die einzige Antwort auf die Ineffizienzen dezentraler Multi-Echelon-Systeme ist.
Die strukturelle Grundlage dieses Berichts bildet ein klassisches vierteiliges Lieferketten-Modell:
• Tier 0 (Retailer): Direkte Schnittstelle zur Kundennachfrage.
• Tier 1 (Wholesaler): Konsolidierungspunkt für den Einzelhandel.
• Tier 2 (Distributor): Zentrale Logistikdrehscheibe.
• Tier 3 (Manufacturer): Produktionsstandort mit Rohmaterialbezug.
Innerhalb dieser Kette erzeugt die Dynamik zwischen Bestellung (Order) und Warenfluss (Goods) zeitliche Verzögerungen (Lead Times), die eine präzise Balance zwischen Lagerhaltungskosten (Holding Costs) und Fehlmengenkosten (Backlog Costs) erzwingen. Um die Überlegenheit moderner KI-Architekturen zu validieren, ist eine rigorose Gegenüberstellung mit klassischen Systemen unter kontrollierten Bedingungen zwingend erforderlich.
2. Methodik und Versuchsaufbau: Szenarien und Akteure
Die Bewertung von KI-Agenten in der Logistik erfordert hochgradig kontrollierte Testumgebungen, um Rauschen von tatsächlicher Entscheidungsintelligenz zu trennen. Unsere Analyse kontrastiert zwei spezifische Supply-Chain-Konfigurationen: „Uniform“ als strukturelle Baseline und „Diverse“ zur Simulation realer Marktasymmetrien.
Parameter | Konfiguration „Uniform“ | Konfiguration „Diverse“ |
Initial Inventory | [12, 12, 12, 12] | [12, 14, 16, 18] |
Lead Times (Lm) | [2, 2, 2, 2] | [1, 2, 3, 4] |
Product Capacities (cm) | [20, 20, 20, 20] | [20, 22, 24, 26] |
Sales Prices | [0, 0, 0, 0] | [9, 8, 7, 6] (sinkend je Tier) |
Order Costs | [0, 0, 0, 0] | [8, 7, 6, 5] (sinkend je Tier) |
Die Komplexität wird durch drei Nachfragemuster (Demand Patterns) skaliert:
1. Constant: Stabiler Bedarf von 4 Einheiten pro Periode.
2. Increasing: Progressiver Anstieg (2+⌈t/3⌉), der die Antizipationsfähigkeit fordert.
3. Decreasing: Degressiver Verlauf (2+⌈(12−(t−1))/3⌉), der das Risiko von Überbeständen maximiert.
Dieser Aufbau erzwingt eine Differenzierung zwischen reaktiven Algorithmen und vorausschauender Intelligenz.
3. Benchmarking klassischer Heuristiken vs. Reinforcement Learning
Die Bewertung autonomer Intelligenz erfordert eine Einordnung gegenüber etablierten Baseline-Methoden. Unsere Daten erzwingen eine Neubewertung der technologischen Reife:
• Legacy-LLMs vs. Reasoning-Modelle: Ein signifikanter Befund ist der "Generationensprung". Während ein Legacy-Modell wie GPT-4.1 eine massive durchschnittliche Optimalitätslücke (Δ) von 418.67 aufweist, reduzieren moderne Reasoning-Modelle wie o4-mini diesen Fehlerwert drastisch. Dies markiert den Wendepunkt von rein sprachbasierten Modellen zu logikfähigen Agenten.
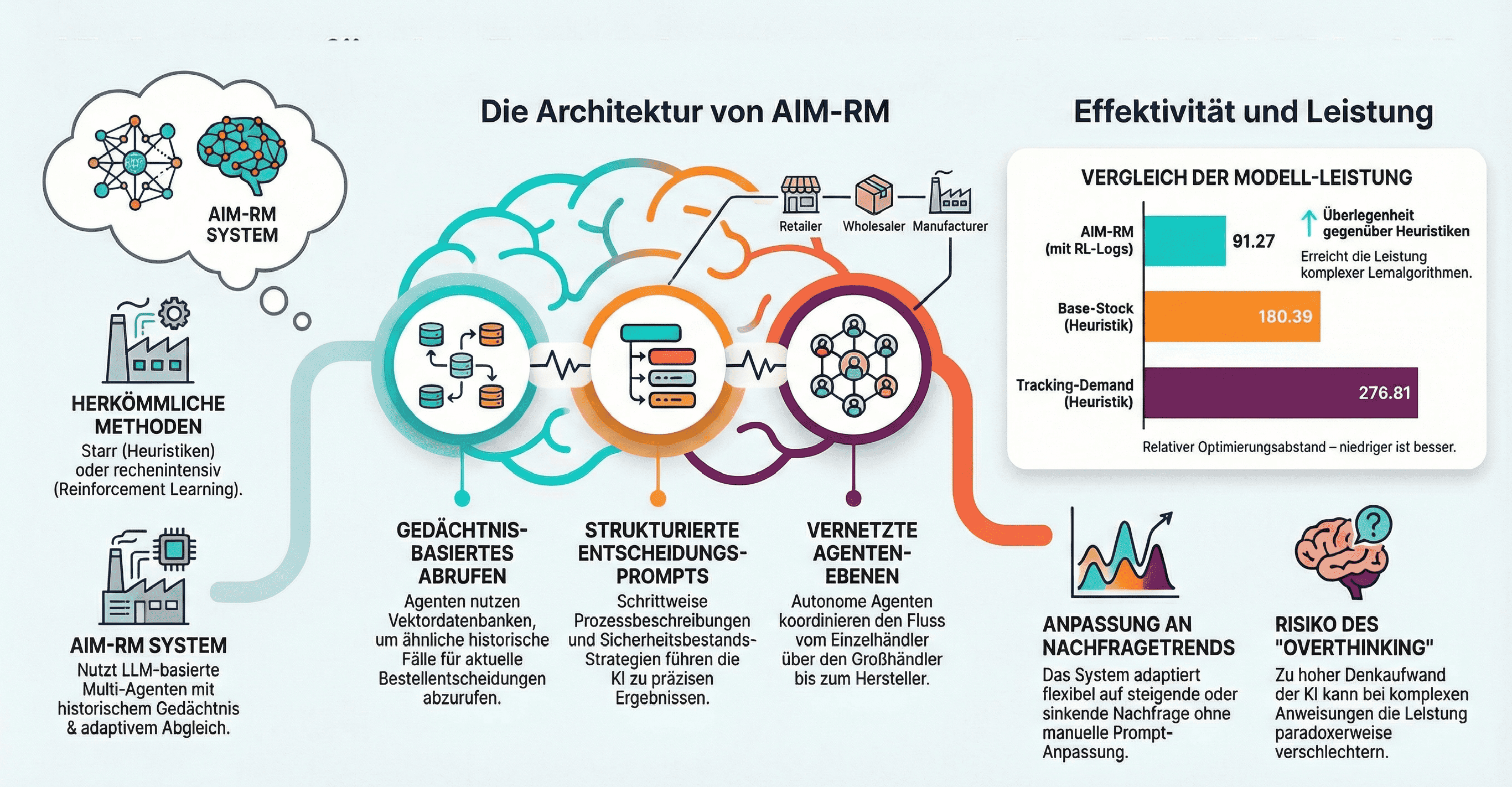
• Heuristiken (Base-Stock & Tracking-Demand): Die Analyse zeigt, dass Base-Stock-Policies (durchschnittliches Δ von 180.39) und Tracking-Demand (276.81) in zeitvarianten Szenarien kläglich scheitern. Ihre Starrheit verhindert jede Anpassung an Trends; sie reagieren rein reaktiv, was in "Increasing"-Szenarien zu massiven Backlogs führt.
• Reinforcement Learning ( & ): Diese Methoden bleiben die mathematische Benchmark. MAPPO erreicht im "Decreasing-Diverse"-Szenario eine Lücke von nur 16.27. Dennoch sind die Implementierungshürden – namentlich die hohe Probenkomplexität und die prohibitiven Rechenkosten für das Training – für die meisten SCM-Praxisanwendungen ohne Simulationsumgebung nicht tragbar.
4. LLM-basierte Multi-Agenten-Systeme: InvAgent-Konfigurationen
Reasoning-Modelle wie o4-mini eröffnen die Möglichkeit, komplexe SCM-Logiken ohne ressourcenintensives Training (Zero-Shot) abzubilden. Die Benchmark-Ergebnisse der InvAgent-Varianten verdeutlichen den Einfluss strukturierter Prompts.
Der Vergleich zeigt, dass die Integration einer expliziten Sicherheitsbestands-Logik im InvAgent (w/ step & SS strategy) die Entscheidungsqualität massiv stabilisiert. Hierbei wird die mathematische Formel für das Target-Bestandsniveau genutzt: target_base≈(Lm+1)⋅μ^ unter Einbeziehung des Sicherheitsbestands SS=z⋅σ^⋅Lm+1.
Besonders hervorzuheben ist das „Constant-Uniform“-Szenario: Hier erreichte der Agent eine relative Optimalitätslücke von 0.00. Dieser "So What?"-Faktor ist von disruptiver Bedeutung: Er belegt, dass LLMs in dezentralen Systemen eine mathematische Optimalität erreichen können, die bisher nur zentralisierten Solvern (wie CP-SAT) vorbehalten war. Dies beweist die prinzipielle Fähigkeit der Agenten zur dezentralen Koordination.
5. Das AIM-RM Modell: Robustheit durch Memory Retrieval
Für volatile Umgebungen ist der Rückgriff auf historische Erfahrungswerte unerlässlich. Das AIM-RM (AI Agent with Memory Retrieval) Modell stellt eine Low-Cost Hybrid Architecture dar, die die Vorteile von RL-Ergebnissen nutzt, ohne deren Trainingskosten zu verursachen.
AIM-RM operiert über ein zweistufiges Modul-System:
1. Memory Module: Speichert Transaktionsdaten und RL-Logs in einer Vektordatenbank.
2. Similarity Matching: Mittels Euklidischer Distanz werden die K=6 ähnlichsten historischen Fälle identifiziert und dem Decision-Making Module als Kontext bereitgestellt.
Die Integration von RL-Logs („w/ RL log“) führt zu einer indirekten Koordination: Obwohl die Agenten dezentral agieren, verhalten sie sich durch die Referenzierung optimaler RL-Entscheidungen systemisch kohärent. Mit einem Average Gap von 91.27 (bei Medium Reasoning) ist AIM-RM (w/ RL log) der top-performer über alle diversen Szenarien hinweg und bietet die notwendige Robustheit, die reinen LLM-Prompts fehlt.
6. Die Paradoxie des „Overthinking“ bei Reasoning-Modellen
Ein kritischer Aspekt für die strategische Planung ist das Phänomen des "Overthinking". Unsere Daten belegen eine kontraintuitive Korrelation: Mehr Rechenaufwand (Reasoning Tokens) führt bei komplexen SCM-Prompts oft zu schlechteren Ergebnissen.
In den Szenarien „Increasing-Uniform“ und „Decreasing-Uniform“ zeigt sich, dass „High Reasoning“ die Systemstabilität untergräbt. Der Mechanismus ist destruktiv: Übermäßig langes "Nachdenken" führt dazu, dass die Modelle versuchen, die Lagerhaltungskosten extrem zu minimieren. Dies resultiert in zu niedrigen Beständen, die bei kleinsten Nachfragespitzen sofort in massive Backlogs umschlagen. Die Folge ist ein künstlich induzierter Bullwhip-Effekt: Abrupte, übersteigerte Bestellsurges der Agenten, die das gesamte Upstream-System destabilisieren.
Strategische Warnung: "Test-Time Scaling" (erhöhte Reasoning-Tokens) ist kein Garant für bessere Logistik; es kann die systemische Instabilität massiv befeuern.
7. Fazit und SCM-Technologie-Roadmap
Die Benchmark-Analyse zeigt deutlich: Die Ära der starren Heuristiken endet. Das AIM-RM-Modell bietet eine robuste, datengestützte Entscheidungsgrundlage, die RL-ähnliche Präzision mit der Flexibilität von LLMs kombiniert. Es stellt den derzeit effizientesten Pfad zur Autonomisierung dezentraler Lieferketten dar.
Für die Implementierung einer zukunftsfähigen SCM-KI-Strategie empfehlen wir:
• Implementierung von Memory-Retrieval-Architekturen: Setzen Sie auf hybride Modelle wie AIM-RM, um historische RL-Logs als „implizite Koordination“ zu nutzen, statt teure, isolierte RL-Modelle von Grund auf zu trainieren.
• Vorsicht bei High-Reasoning-Konfigurationen: Begrenzen Sie den Reasoning-Aufwand auf ein moderates Maß. Unsere Daten zeigen, dass technisches Overthinking das Risiko von Lieferketten-Instabilitäten und abrupten Bestellspitzen drastisch erhöht.
• Hybride Prompt-Strategien: Kombinieren Sie Prozessbeschreibungen mit harten mathematischen Anchors (Safety-Stock-Formeln), um die Halluzinationsrate der Agenten in numerischen Grenzbereichen zu minimieren.
Die Zukunft globaler Lieferketten liegt in dezentralen, lernfähigen Agenten-Systemen, die durch kollektive Erfahrung und moderate Reasoning-Tiefe die Resilienz des Gesamtsystems sicherstellen.


